- Tom Dekan
- Posts
- 💡7 bullets: Quality will make you pay, AI fake wisdom
💡7 bullets: Quality will make you pay, AI fake wisdom
Tom Dekan
July 12, 2025
Joke: What’s an AI’s coding assistant’s favorite food?
(Answer below ⬇️)
Upgraded personal blog: I upgraded my personal website yesterday.
It’s more minimalistic with higher quality UI throughout, with some subtle animations thanks to Framer Motion.
A cool part? It automatically pulls in my latest two YouTube videos using the YouTube Data API, updating hourly.
This is easy with Next's revalidate code (see arrow below):
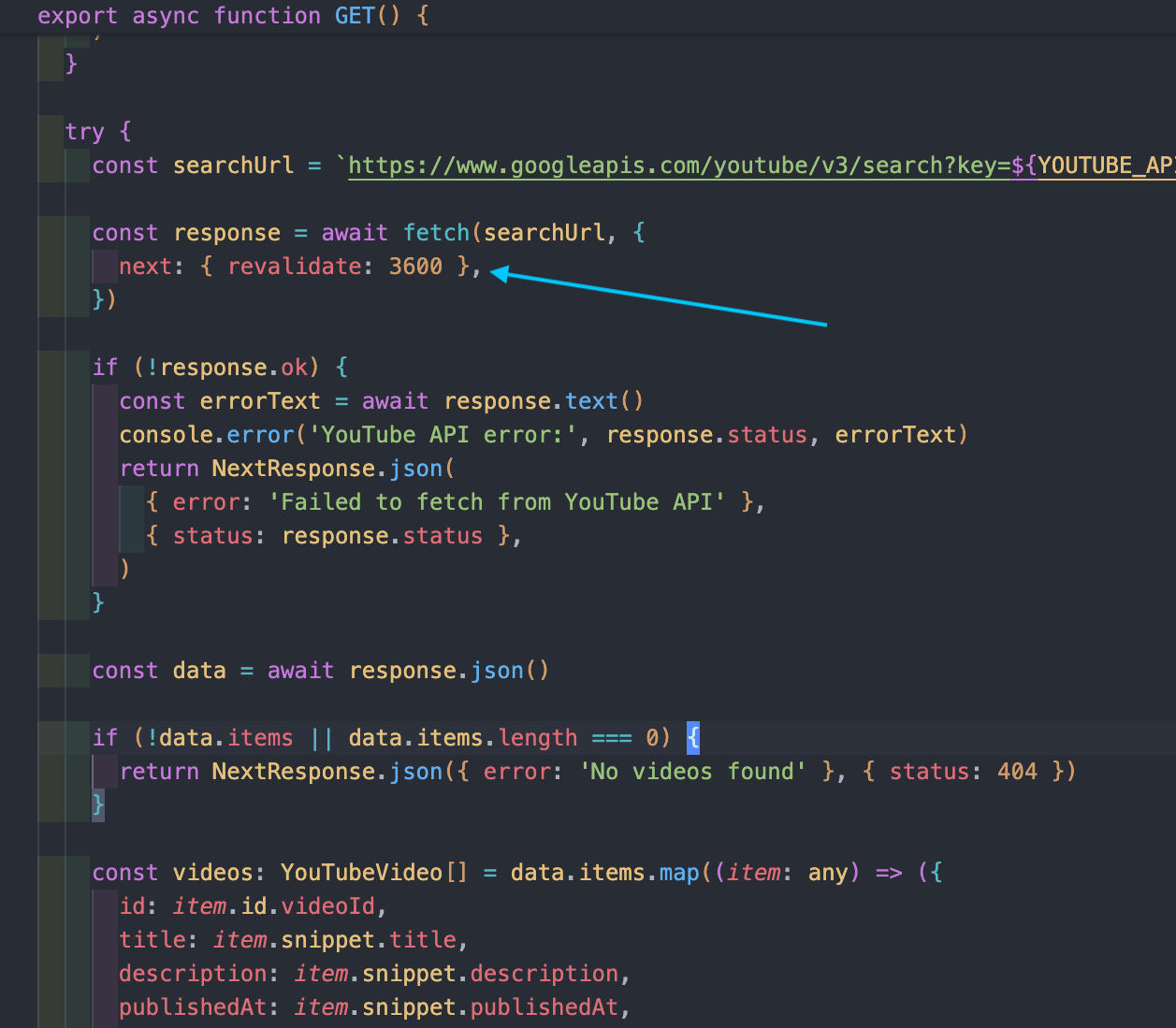
Next's re-validate code (aka, Incremental Static Generation) to fetch my latest YouTube videos
Quality will make you pay: My site update was a lesson in itself. Even with AI-assisted development, these changes took around three hours of real time.
You might think it's "just a landing page" or "it's just a blog".
Quality doesn't care and will make you pay regardless.Keep scope small (Use Django): This highlights the importance of keeping your scope incredibly small, especially for solo founders. Launch fast, with something as small as possible. Django is awesome for this.
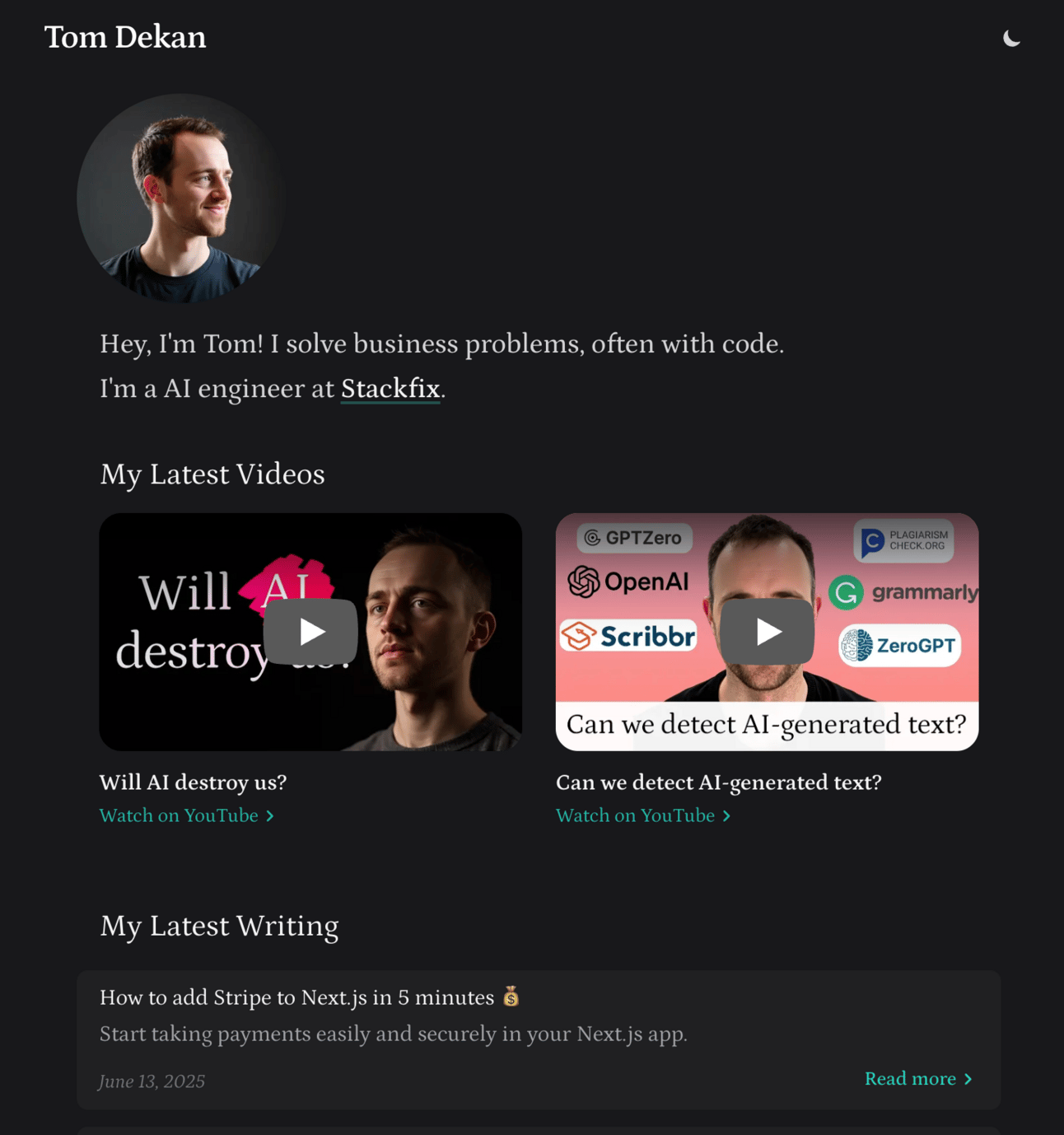
My upgraded personal site
Recommendation: I've been using Pydantic-AI this week when building a >1M token synthetic dataset for testing LLM retrieval. It provides a clean way to interact with models. I'll be using it as my standard driver when working with LLMs from now on.
Skepticism of AI wisdom: There's a widely held belief that LLMs have a "U-shaped" attention span, focusing on the start and end of their context window.
This sounds plausible, but I don't know this from primary evidence. I've just heard people saying this.
AI is nascent field with lots of uncertainty. It's good to avoid absorbing people's plausible-sounding theories as facts. (Side note, I plan to test this U-shaped pattern with my dataset this week).Broken benchmark: I've discovered that a industry-standing benchmark for testing LLM retrieval is fundamentally flawed.
Lots of companies proudly boast on their websites of their score on this particular benchmark. This isn't a minor issue; it makes the benchmark useless. I've drafted a writeup on this; looking forward to sharing this with you in full.Gamed benchmarks. This leads to a broader skepticism of benchmarks. Models are being trained on the benchmarks themselves (e.g., Meta's Llama 4). Developers are smart and will find this out. Relatedly, see Why Eval Startups Fail.
Anti-recommendation: LangFuse & LangChain. I looked into LangFuse for LLM monitoring and logging. Multiple obvious elements are missing (e.g., adding to logging). While unconnected, I've heard strongly negative things about LangChain as well.
Question: Our startup is currently asking: "What are the most boring problems in AI?
Best from London in a heatwave ☀️
Tom
P.S I did a DEXA body composition scan last week just for the data (I recommend it).
The first image is before I was married and the second photo is after.
Can you see the difference? 🙂
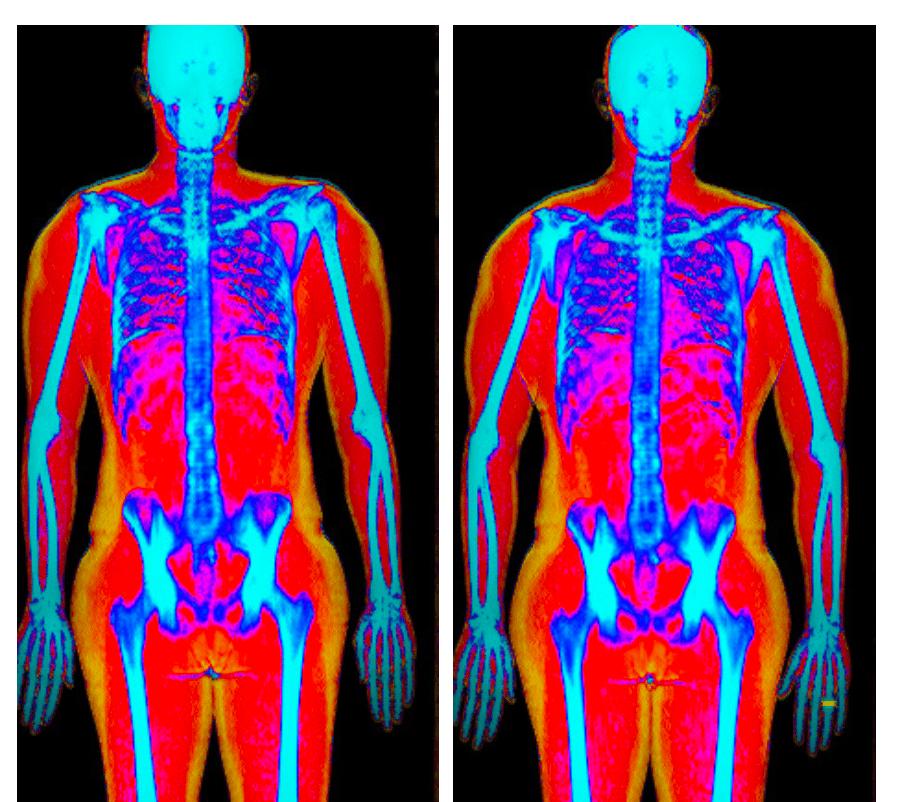
October 2024 on the left. July 2025 on the right.
Joke: What’s an AI’s coding assistant’s favorite food?
Spaghetti, just like its code. 🎉